“AI绘画“是2022年抖音上最火的一款特效玩法,用户只要输入一张图片,AI就会根据图片生成一张动漫风格的图片。由于生成的图片效果带有一定的“盲盒”属性 ,画风精致唯美中又带着些许的蠢萌和无厘头,一经上线就激发了广大用户的参与热情。抖音特效对AI技术有过很多应用实践,2021年的”漫画脸”特效也是一款上线3天千万投稿的爆款,使用的是GAN技术。
这一次,抖音的”AI绘画”使用了时下最火的多模态生成技术。这是由文本生成图片/视频/3D等跨模态的生成技术,具体地说,是通过大规模数据的训练,仅通过文字或少量其他低成本的信息引导,可控地生成任意场景的图片/视频/3D等内容,在AIGC等方向有极大的潜在应用价值。
据了解,随着DALL·E的问世,2021年初字节跳动智能创作团队就开始了相关技术的跟进和规划,今年8月底Stable Diffusion发布后,抖音特效团队很快启动了”AI绘画”这个项目。
Stable Diffusion是一个文本生成图像的多模态生成模型,相比于GAN,Stable Diffusion的多样性和风格化会更强,变化的形式也更丰富,同一个模型可以做很多不同的风格。同时,后者对性能和计算资源要求大幅下降,其自身开源的属性,还可以进行各种fine tune,调用和修改。
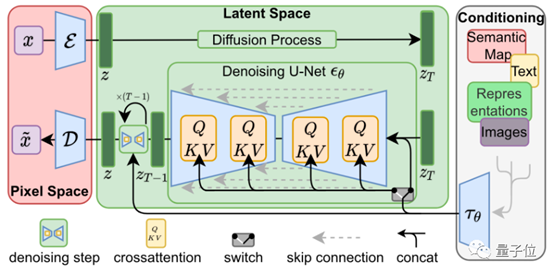
图1 基础模型架构
Stable Diffusion的逻辑是,用一个图像对应一个文本标注的形式去训练模型,一个“文本+图像”组成一个数据对,先对其中的图像通过高斯分布进行加噪,加完噪声之后,再训练一个网络去对它进行去噪,让模型可以根据噪声再还原出一个新的图像。
为了能够使用文字控制模型生成的内容,Stable Diffusion使用了预训练的CLIP模型来引导生成结果。CLIP模型使用了大量的文字和图片对训练,能够衡量任意图片和文本之间的相关性。在前向生成图片的过程中,模型除了要去噪以外,还需要让图片在CLIP的文本特征引导下去生成。这样在不断生成过程中,输出结果就会越来越接近给定的文字描述。
抖音”AI绘画”是采用图片生成图片的策略,首先对图片进行加噪,然后再用训练好的文生图模型在文本的引导下去噪。
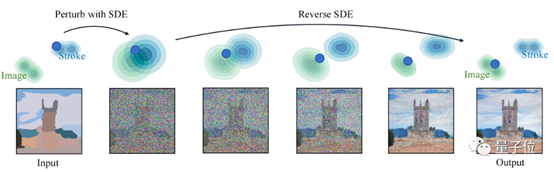
图2 图片生成图片的逻辑过程
作为技术支持方,字节跳动智能创作团队在Stable Diffusion开源模型的基础上,构建了数据量达十亿规模的数据集,训练出两个模型,一个是通用型的模型Diffusion Model,可以生成如油画、水墨画风格的图片;另外一个是动漫风格的Diffusion Model模型。

图3 通用模型Diffusion Model生成的图像风格

图4 动漫风格的Diffusion Model模型生成的图像风格
漫画风格模型是采用“漫画图像+文本”的数据对进行训练。为了让动漫风格模型生成的效果更好更丰富,字节跳动智能创作团队在动漫风格模型优化训练的数据集里特别加入了赛博朋克和像素风等不同风格的数据。
抖音特效在动漫风格上有过比较丰富的探索,观测了此前用户对不同风格的反馈,抖音”AI绘画”此次选用的就是精致漫画风的动漫风格。
在算法侧调优的同时,字节跳动智能创作团队为抖音特效产品侧提供了文本的接口prompt,方便产品侧对效果进行进一步的微调,通过输入文字,让生成的图片效果更加贴近于期望中的样子——风格化程度“不会特别萌、跟原图有一定相似度,但又不会特别写实”。
此外,模型还同时采用正向、负向文本引导生成的策略。除了描述生成图像内容、风格的正向条件外,还通过负向引导词(negative prompt)优化模型生成结果。通过在生成效果、生成内容等方面进行约束,可有效提升模型在图像细节上的生成质量, 并大大降低生成图像涵盖暴力、色情等敏感内容的风险。
链接:https://mp.weixin.qq.com/s/8qaIm7zUbIPkztwjAJaJJw

